Wormholes in the Latent Space

In my recent quest to integrate my video synthesis work with text to image AI, I ran into an issue: writer's block. Sometimes you just don't know the type of image you want to create, especially if, like me, you are aiming for more abstract images. Alternatively, let's say you have a concept for an image, but you don't quite know how to take it further.
Enter EvoGen
EvoGen is a Colab notebook by Magnus Petersen. It generates a slew of images using randomized prompts and runs them through a model which gives them an aesthetic score. It takes the images that score the highest and evolves them in the next generation to try to improve its aesthetic score. The words in the randomized prompts come from lists of artists, art genres, the English dictionary, or a custom list that you feed it.
Where this is really interesting to me is that some of the aesthetically beautiful images it creates come from absolute gibberish-looking prompts. It connects completely unrelated concepts and ideas, creating wormholes in the latent space. It's cut-up technique, Dadaism, and surrealism applied to prompts, but with a fun genetic twist. The prompts are not anything that a human would come up with, but they are something that a human can use and refine for their own purposes.

Suitcases? 18991974? No one would naturally feed that into a prompt. The (seaphantasm:0.2) is my doing, however. In this case, I am working with my own fine-tuned model based on my video synth work. And elements of it are definitely in that image.
EvoGen on Your Own Models
The stock EvoGen notebook assumes that you are evolving prompts for vanilla Stable Diffusion 1.5. There's nothing wrong with that, but if you want to work with this aesthetic grading on your own fine tuned models you need to do a couple things first.
Conversion
Short version: EvoGen needs to generate a lot of images to do what it does, so your model needs to be converted into a format that will allow it to do that efficiently.
Longer, technical version: EvoGen uses TPUs rather than GPUs to generate 8 images in parallel. To use the TPUs, though, you need to have a model that is not in PyTorch format, but in Flax format. Furthermore, you will blow up the memory on Colab if you use the default float32 precision, so you need to cut that in half and use bfloat16 (bf16) precision.
Running EvoGen
We need to make a few minor edits to the EvoGen notebook to use our custom model. Run everything up to the Load the Model cell. Hit Show code and change:
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5", revision="bf16", dtype=jnp.bfloat16)
to:
pipeline, params = FlaxStableDiffusionPipeline.from_pretrained("/path/to/your/converted/model", dtype=jnp.bfloat16)Add your path and remove revision="bf16", basically. Run that cell and the following two cells.
When it comes to the custom words, here is where you put in your fine tuned token. If you just want to let 'er rip and see what happens, your token is the only thing you should enter here. It's worth doing that once just to see what happens.
You may find (as I did), that the full-weight of your token overpowers the rest of the generative prompt. Decreasing the weight (<token>:0.1, etc.) will certainly help, but once the process creates longer and longer prompts (as it is wont to do), it might not be strong enough to influence the image anymore. Something to try is giving it a range of weights to randomly pick from and let the aesthetic scoring figure out which weight works best in which length prompt (and at what position in the prompt). Like so:
custom_words = ["<token>:0.1", "<token>:0.15", "<token>:0.2", "<token>:0.25", "<token>:0.3"]If you are trying to generate a specific type of image–let's say, a landscape–prepend your token with that keyword.
custom_words = ["landscape <token>:0.1"]I've found that keeping the keyword small helps here, because EvoGen will fill in the gaps. If you'd like more variation, add synonyms as individual entries:
custom_words = ["landscape <token>:0.1", "terrain <token>:0.1", "countryside <token>:0.1", "topography <token>:0.1"]One gotcha for this approach is that your synonyms may mean something else to Stable Diffusion. I tried to get variations on an eye, so I entered eye, eyeball, pupil, iris. Pupil generated some student-teacher scenes. Iris gave me lovely images of the flower.
Once you've set up your custom words, run the cell.
In the next cell, the only thing that you need to do is check the require_custom_words box. This will force EvoGen to use at least one of the words in your custom_words list, triggering the use of your fine tuned token.
Some settings I would suggest, having played with this notebook for a bit: I would set prompt_length_min to at least 5. We know that Stable Diffusion does aesthetically better with longer prompts, and this will help it in that direction. I would also change seed to a set number. If you're using a random seed each time, you're not exactly testing the viability of the prompt, but testing the viability of the prompt + the random seed. You can always take good prompts and randomize the seed later.
Beyond that, tweak the parameters between runs and see how it works for you. The parameters are (thankfully) well-documented in the notebook. A full run of 25 generations takes between 2-4 hours.
Results
One of the cool things that EvoGen does is graph the increase in aesthetic score over time.
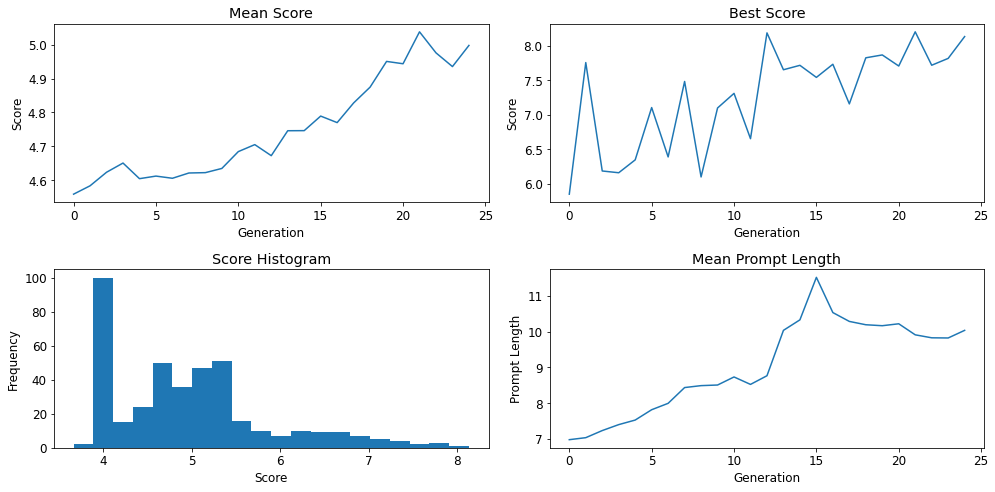
By default, EvoGen will run for 25 generations. I've found that after about 10 generations, you'll have a pretty good idea whether that run will breed outputs to your liking. With each generation, it'll also give you the 9 highest-scoring images as well as their prompts. It is worth looking at each generation's images as you may prefer images/prompts from generation 12 over generation 25. It's still a matter of taste.
Speaking of taste, the aesthetic scoring is not without its flaws. Over on its GitHub page, it documents its known biases. In my experience, I've found that the scoring does not favor abstract images. As someone who works abstractly, that's unfortunate. If you know, however, that is your goal, put abstract into your custom_words so that the system is scoring all abstract images and not trying to compare it against portraiture.
Genetic systems being what they are, they will latch onto well-performing traits and pass them on to future generations. One of my runs randomly struck on Thomas Kinkade as an aesthetic keyword that scores highly. The Painter of Light™ is not really my aesthetic at all, but the images kept scoring highly. It would not let the man go, so I had to kill off that run and try again.
The list of artists and styles/genres are stored in CSV files in the EvoGen repository. As I am trying to generate prompts that work with my specific data set, it would be worthwhile for me to curate these lists to be more to my taste.
Conclusion
In one of my runs, EvoGen really wanted to mix 18th- and 19th-century portraiture with a video synth aesthetic. This is not a combination that I would have reached for, but I love the results. This is the power of a tool like this. Sometimes you really need to throw spaghetti at the wall (in a thoughtful manner) to strike on something new. Writer's block solved.



