Portrait of the Artist as a French Canadian Pop Sensation

Like a lot of people that work with art and tech, I'm fiddling around with AI in my spare time. The possibilities are definitely exciting, even if it feels like the wild west at times.
As someone that has a pretty clear artistic process and aesthetic sensibility, picking up a new medium can be tough. You want your point of view to come through in this new way of working; but it is a new way of working. For the first couple tries, it definitely feels like you're exploring how everyone else does it.
I've done some work in the past with GANs, but right now I'm playing with everyone's favorite new toy: text-to-image generation.
Core Text
A big part of text-to-image processing is crafting the text prompts that generate images. Being overly verbose helps. Adding in seemingly unrelated keywords can help. Working within this text system definitely is an art to itself. Yes, it's a lot of trying things, finding out they didn't quite work and adjusting your approach. It's very alchemical. It's not quite the "click the button, get the art" situation, as it is often portrayed.
My starting point was trying to generate images that look like my video work. Out of the gate, I found text-to-image tools to be poorly suited for the task. The work on these models is aiming towards highly detailed compositions, with an eye towards photorealism, or at least highly stylized illustrations. My standard definition abstract blobs and blocks are little hard to pin down in that world. I was literally at a loss for words.
I then employed two tools: CLIP Interrogator and Lexica to help me figure out what I do, in prompt terms. CLIP Interrogator accurately analyzed stills from my work as being "video art", but when I fed the resulting prompts back into Stable Diffusion, I got a lot of images that were accurate to the prompt, but not accurate to my taste or aesthetic. Uploading my stills to Lexica resulted in prompts that accurately described my taste and aesthetic (and color palette!), but were more figurative that I normally create. So I had to slam the two together.
One quirk that I noticed: I needed to explain to the AI in concrete terms abstract shapes. When I was looking for winding, echoing sine waves, I needed to use spaghetti or intestines in my prompts. I found that using maps or continents was good for irregular blob shapes. I've never had to think about the components of my work in this way. It's like collaborating on a piece with Amelia Bedelia.
I spent an hour or two revising prompts, trying out different combinations, generating a pile of images that I really liked.







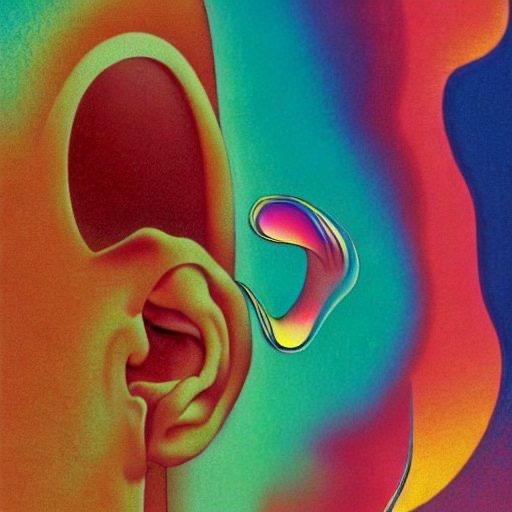

Celebrity Cameo
One of the images I generated was a very surreal portrait of early 90s popstar Céline Dion. In this image, she's got borderline Ziggy Stardust makeup, but is otherwise a disembodied head screaming in an ocean of muscle tissue.
Artists working in the text-to-image space will sometimes have celebrities pop into their images due to prevalence in the data set. This was not really one of those cases. After a few rounds of images, I was working on possible revisions to a prompt that was working well. For some reason, the prompt included "portrait of the band Guns N' Roses", so in coming up with a prompt revision, I went with a musician that could be the polar opposite of GNR. Casting against type, as it were.
But I fell in love with this image. It's so strange. It is in complete contrast to her adult contemporary diva image. She does not have an edgy bone in her body, but plopping her into this Jodorowsky-esque hellscape with a half-screaming/half-singing rictus gave her a strange appeal.
I don't really work in stills, though. I needed to figure out a way to get her to move.
It's All Coming Back to Me
Since I had a pretty clear, relatively straight-on image of a face, I figured that the best approach would be to deepfake the Ziggy Dion portrait with video. And what better video to animate an abstraction of Céline Dion than with Céline Dion herself?
After some youtube-dl and ffmpeg magic, I had a cropped clip from the music video of It's All Coming Back to Me Now. The clip is was only a couple seconds, but it was enough to see if I could make it work.
As an aside, music videos–even ones for elaborate adult contemporary ballads–are cut extremely quickly. Finding even a couple seconds of her singing with little else happening in a seven and half minute music video was nigh impossible. I scanned through a couple live performances as well with similar results. 🤷
In order to perform the deepfake, I used the Face Image Motion Model colab notebook. Honestly, I could have worked with some faceswap apps or an all-in-one deepfake package. That would have probably done the trick. But I like to make things hard for myself as I learn how these systems work, so raw colab notebook it was.
What's wild about the AI space is the absurd pace of obsolescence. That colab notebook is scarcely 18 months old and it is effectively broken. A lot of the necessary tools it needs to run are no longer accessible from the notebook. The training data is missing. I had to source those files from a Google drive link I found in a comment on a blog. It's good that I'm comfortable with programming and troubleshooting error messages because that is the only way to get this notebook from 2021 running in 2022.



The first attempt, well, it had some issues. Due to facial alignment differences between the music video clip and Ziggy Dion, it caused a lot of tearing and distortions of the face. The most notable is the double mouth.
If I was going to have to control for facial alignment, well then I would need a controlled performance I could work with. After I brushed up on the lyrics, I jumped in front of my webcam and gave it my all.

After some trimming and cropping, the framing matched pretty closely to what I was trying to animate. The alignment was still off, due to my lack of Quebecois bone structure. To remedy this, I took it into Apple Motion. With an onion skinned version of Ziggy Dion over top of the video, I distorted my way into a decent alignment and then exported the video.
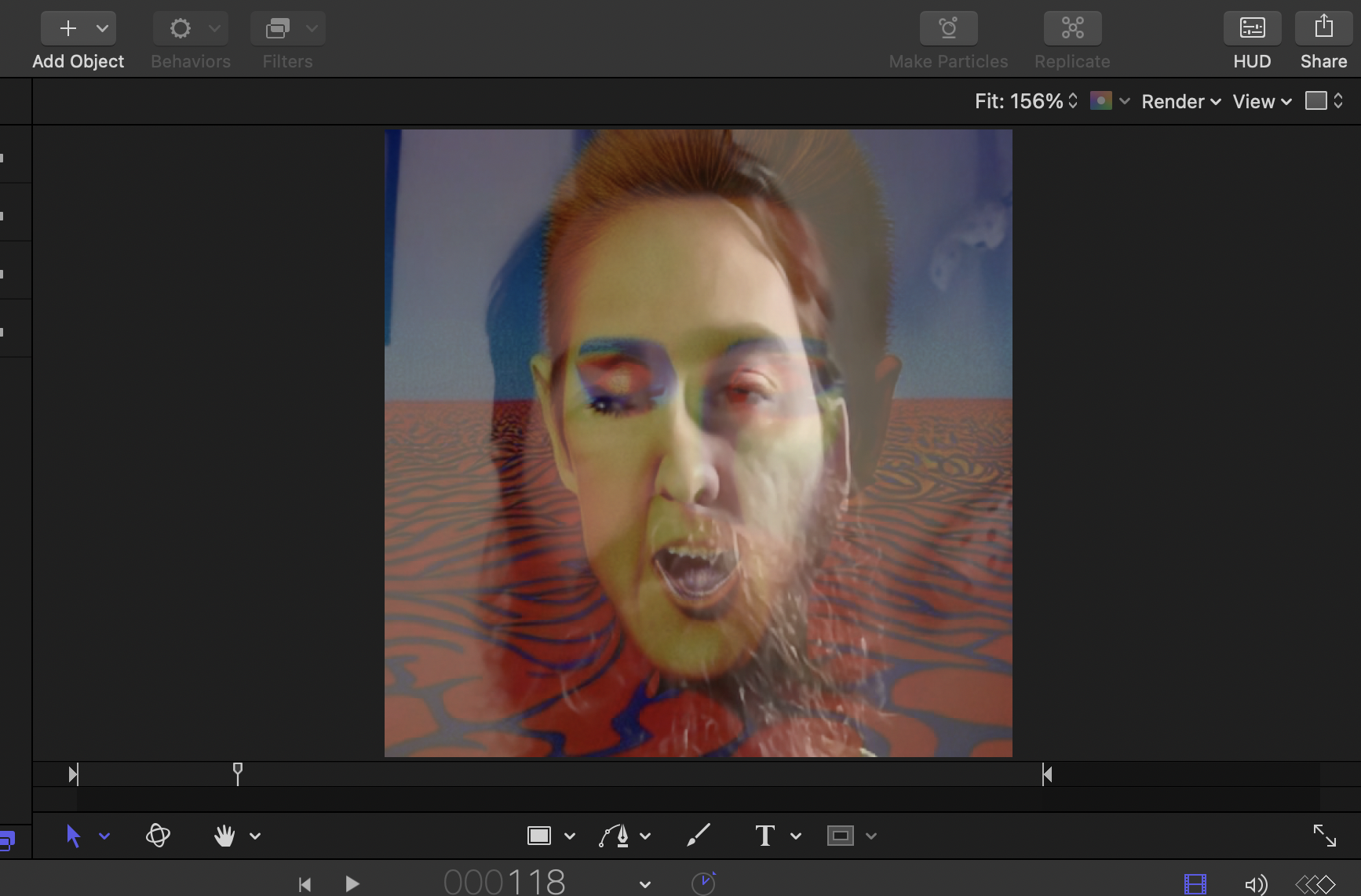
I ran the separate pieces back through the colab notebook and was pretty happy with the results. The final steps involved running the video through Topaz Video AI, which served both to upscale and remove a lot of jitter from the deepfake, as well as one final run through Motion to add in the soundtrack.
Here is the final result. (You'll need to click through. The copyright on the song is preventing me from embedding the video here.)
It's glitchy, sure, but for a couple hours work over a weekend, not bad at all. The biggest issue seems to be that the manipulated image has an open mouth and the AI model does not know how to interpret that. It also doesn't quite know how to work with the surreal background, but honestly I love some of the warping around the face.