An AI of Me

In my various experiments with AI, one thing I've been after is a kind of video synthesis aesthetic applied via AI. Video synthesis has a certain look, but it's not a look I'm seeing explored too deeply in other AI works, whether it's with GANs, text to image generation, or other techniques. At some point, I'll write about my experience with StyleGAN, but for today, let's focus on Stable Diffusion (1.5 for now, 2.0 is still the wild west as of this writing).
Part of the issue–perhaps the main issue–with text to image replicating a video synthesis style is that it's not in the dataset. If you search "video art" or "video synthesis" in haveibeentrained.com, you get this:
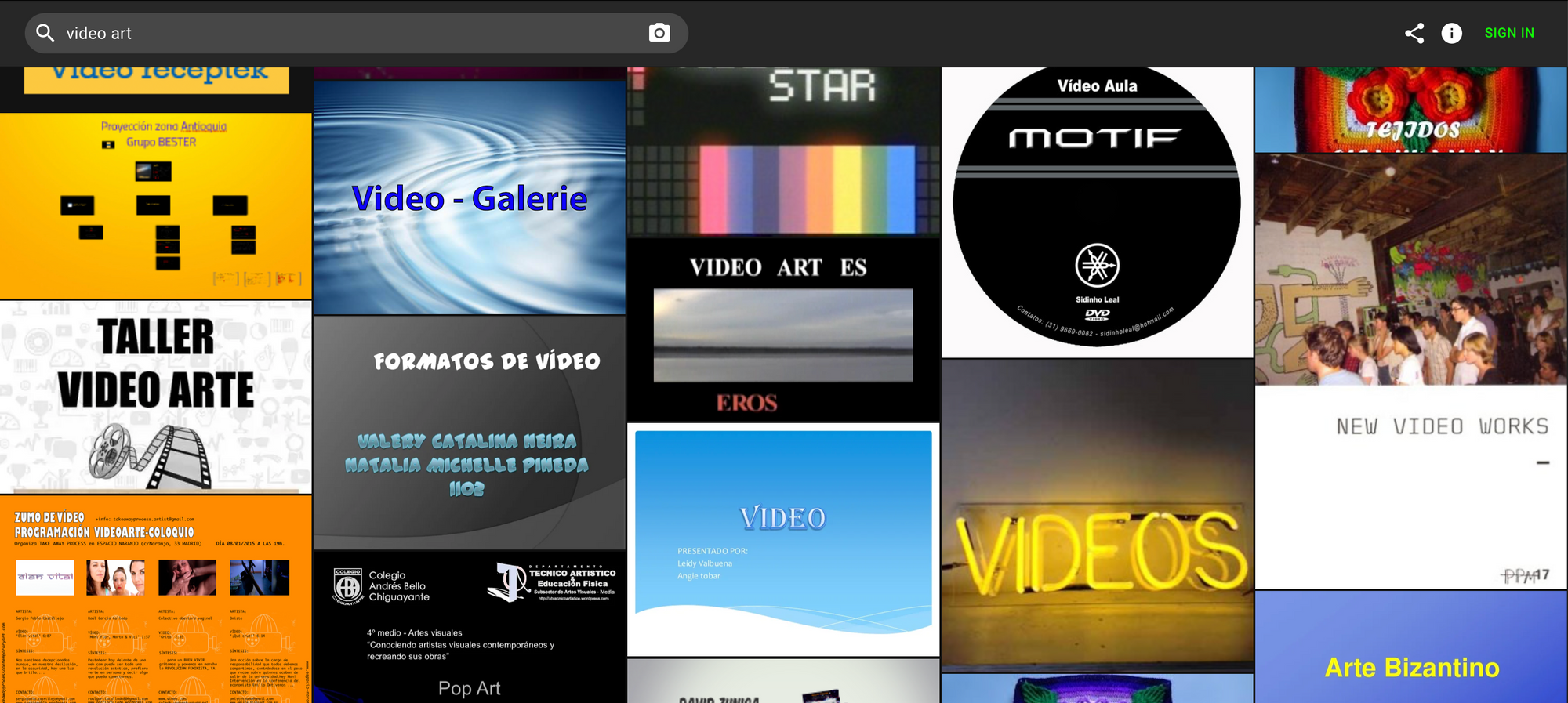
It's pages and pages of PowerPoint slides and very few image examples of what I'm after.
Okay, so the data set will not respond to the keywords with an aesthetic I am after, maybe I need to craft different keywords. Feeding some stills of my work into CLIP Interrogator yielded a couple interesting keywords. "JPEG artifacts" came up for a couple images (the jagged SD quality probably accounts for that). "Inspired by Victor Moscoso" also came up, which is honestly pretty accurate.


Otherwise I got a lot of "colorful", "rainbow", "psychedelic" "abstract", which are pretty generic descriptors. Feeding that back into Stable Diffusion did not turn out what I'm after.
In order to fix that, we need to tell Stable Diffusion exactly what we're after using a technique called Textual Inversion. For this, you give it between 10-30 images and you train those images into the dataset with a specific key that you can reference when writing your prompts.
I pulled together 30 stills of my work and prepped them for training (resized, cropped, etc.).






With 30 images, the the DreamBooth colab notebook suggests training for 6000 steps. I saved a checkpoint every 2000 steps to see what effect amount of steps has on output. For style training, the notebook suggests a strength between 10-20%. I ended up training 4 models at 5%, 10%, 15%, and 20%. Training each model took roughly an hour and 45 minutes.
My video synth work is largely abstract, blobby, op-art-influenced colored shapes, but I am really interested in applying that style to more photorealistic subjects. In order to test these models, I fed a portrait image into CLIP Interrogator to get a base prompt:
portrait of a person wearing a hat, featured on cg society, precisionism, real life photo of a man, taken with canon eos 5 d, creative commons attribution, portrait of an old man, anamorphic widescreen
I then inserted my key into the prompt to trigger the style influence. One interesting thing I found is that the placement of the key in the prompt drastically influences the result. At the beginning of the prompt was too strong of an influence even in the least trained of the models, at the end was perhaps not enough. I tried weighting different elements of the prompt (and the key) and moving the key around within the prompt. In the end, I have a slightly increased weighted key in the middle of the prompt.
I also found out that the CFG Scale parameter had a significant influence on how the model was used as a style. In my case, a low CFG Scale (2 or 3) was better. A higher CFG Scale resulted in more color influence in the image, but made the photorealistic elements more cartoony.

In order to figure out which model would work the best for my intended use, I ran a semi-scientific comparison using the same prompt, same parameters, same seed, but just swapping out the models.




The more the training strength increased, the closer it got to the training images in style and composition. This is about what I expected. I also noticed that image output was heavily influenced by the seed. The seed in the top right was almost always a pure abstraction with little of the figure visible.
Let's compare the same results at 4000 training steps:




There's definitely more of a figure visible, even at the highest training strength. Again, you can see how seed dependent the output is with how the top right seed behaved.
And let's see at 2000 steps:




These were the models where I'd get the most photorealistic people, but it would almost always apply the style as a kind of background behind the figure. It would also apply it as a fabric texture in a hat or shirt, but leave other aspects of the image alone.
Conclusions
Textual Inversion definitely works for inserting your own work into the model. I could not get these kinds of images out of the base Stable Diffusion model and I have certainly tried. It feels a little finicky about how it's applied. This may just take a lot of prompt engineering and hitting on a good seed to get a good result. For applying a style to more figurative prompts, lower strength and less training steps seems to be the way to go.
While my focus right now is applying an unnatural style to naturalistic images, I'd also like to work on the other end of the spectrum and generate abstract videos from an AI trained on my videos. I need to train a model at a much higher strength and do more of a deep-dive into Deforum, but here's a first pass:
